
What is VQA?
VQA is a new dataset containing open-ended questions about images. These questions require an understanding of vision, language and commonsense knowledge to answer.
- 265,016 images (COCO and abstract scenes)
- At least 3 questions (5.4 questions on average) per image
- 10 ground truth answers per question
- 3 plausible (but likely incorrect) answers per question
- Automatic evaluation metric
Subscribe to our group for updates!
Dataset
Details on downloading the latest dataset may be found on the download webpage.
-
April 2017: Full release (v2.0)
Balanced Real Images
- 204,721 COCO images
(all of current train/val/test) - 1,105,904 questions
- 11,059,040 ground truth answers
- ⊕
July 2015: Beta v0.9 release
- ⊕
June 2015: Beta v0.1 release
Papers
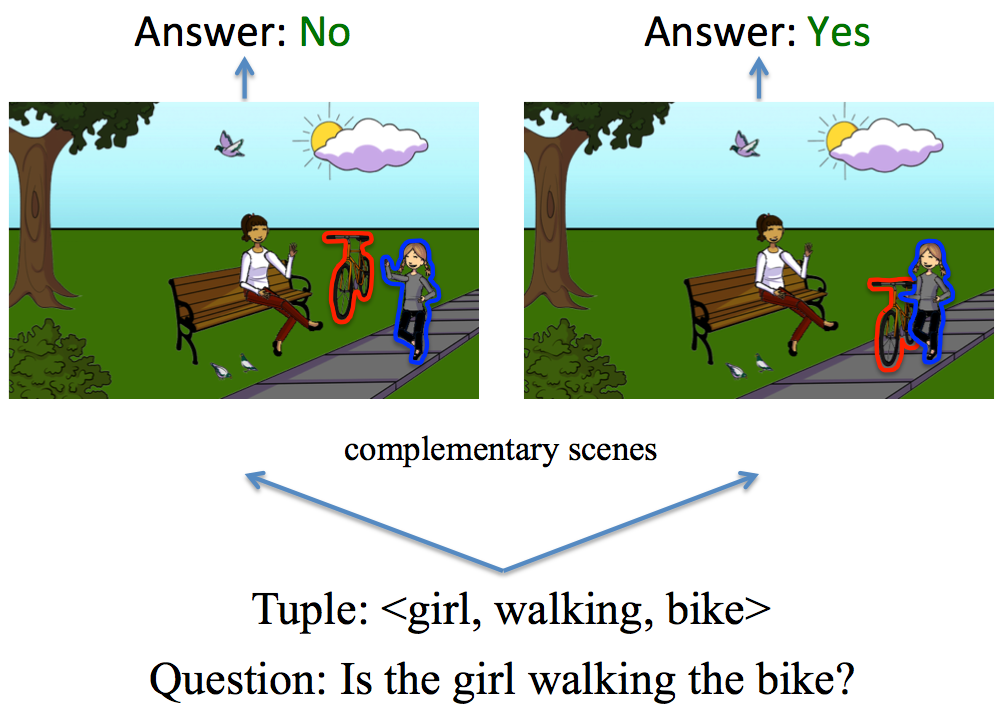
Making the V in VQA Matter: Elevating the Role of Image Understanding in Visual Question Answering (CVPR 2017)





Videos
Feedback
Any feedback is very welcome! Please send it to visualqa@gmail.com.