
|
9 AM - 10 AM PT |





|
Panel-1: Future Directions
Vittorio Ferrari, Damien Teney, Raquel Fernández, Aida Nematzadeh, Olga Russakovsky Hosted on Zoom, joining link on the internal CVPR website: Link (Panel ended) Recording available now: [Video] |
|
12 PM - 1 PM PT |

|
Live QA-1
Individual live QA for challenge related talks and poster spotlight presenters. Hosted on Gatherly, joining link on the internal CVPR website: Link |
|
3 PM - 4 PM PT |





|
Panel-2: Future Directions
Justin Johnson, He He, Mohit Bansal, Katerina Fragkiadaki, Anirudh Koul Hosted on Zoom, joining link on the internal CVPR website: Link (Panel ended) Recording available now: [Video] |
|
12 AM - 1 AM PT |
|
Live QA-2
Individual live QA for challenge related talks and poster spotlight presenters. Hosted on Gatherly, joining link on the internal CVPR website: Link |
Visual Question Answering Workshop
at CVPR 2021, June 19
Zoom and Gatherly links on CVPR 2021 website: Link
Navigate to: Workshops -> Sat, June 19 -> Search for "Visual Question Answering" workshop entry
|
Recording: [Video] |
Panel-1: Future Directions
Vittorio Ferrari, Damien Teney, Raquel Fernández, Aida Nematzadeh, Olga Russakovsky Hosted on Zoom, joining link on the internal CVPR website |
Starts June 19, 9 AM PT! |
|
|
Live QA-1
Individual live QA for challenge related talks and poster spotlight presenters. Hosted on Gatherly, joining link on the internal CVPR website |
Starts June 19, 12 PM PT! |
|
Recording: [Video] |
Panel-2: Future Directions
Justin Johnson, He He, Mohit Bansal, Katerina Fragkiadaki, Anirudh Koul Hosted on Zoom, joining link on the internal CVPR website |
Starts June 19, 3 PM PT! |
| Live QA-2
Individual live QA for challenge related talks and poster spotlight presenters. Hosted on Gatherly, joining link on the internal CVPR website |
Starts June 20, 12 AM PT! |
Home Program Poster Spotlights
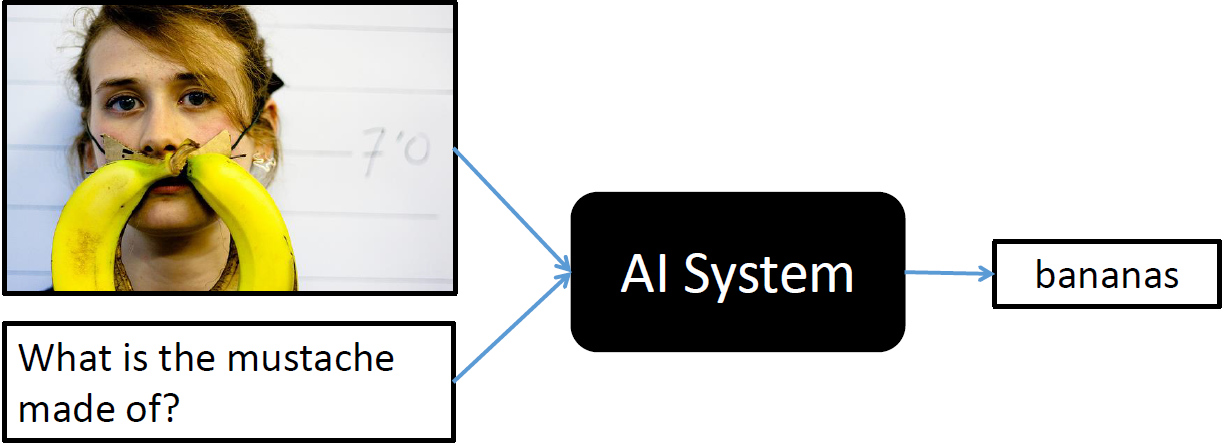
Introduction
The primary goal of this workshop is two-fold. First is to benchmark progress in Visual Question Answering.
-
There will be three tracks in the Visual Question Answering Challenge this year.
-
VQA: This track is the 6th challenge on the VQA v2.0 dataset introduced in Goyal et al., CVPR 2017.
The 2nd, 3rd, 4th and 5th editions were organised at CVPR 2017, CVPR 2018, CVPR 2019 and CVPR 2020 on the VQA v2.0 dataset, and the 1st edition was organised at CVPR 2016 on the VQA v1.0 dataset introduced in Antol et al., ICCV 2015.
VQA v2.0 is more balanced and reduces language biases over VQA v1.0, and is about twice the size of VQA v1.0.
Challenge link: https://visualqa.org/challenge
Evaluation Server: https://evalai.cloudcv.org/web/challenges/challenge-page/830/overview
Submission Deadline: Friday, May 7, 2021 23:59:59 GMT () -
TextVQA: This track is the 3rd challenge on the TextVQA dataset introduced in Singh et al., CVPR 2019.
TextVQA requires models to read and reason about text in an image to answer questions based on them.
In order to perform well on this task, models need to first detect and read text in the images.
Models then need to reason about this to answer the question.
The 1st edition and 2nd edition of the TextVQA Challenge were organised at CVPR 2019 and CVPR 2020.
Evaluation Server: https://eval.ai/web/challenges/challenge-page/874/
Submission Deadline: May 14, 2021 23:59:59 GMT () -
TextCaps: This track is the 2nd challenge on the TextCaps dataset introduced in Sidrov et al., ECCV 2020.
TextCaps requires models to read and reason about text in images to generate captions about them.
Specifically, models need to incorporate a new modality of text present in the images and reason over it and visual content in the image to generate image descriptions.
The 1st edition of the TextCaps Challenge was organised at CVPR 2020.
Evaluation Server: https://eval.ai/web/challenges/challenge-page/906/
The second goal of this workshop is to continue to bring together researchers interested in visually-grounded question answering, dialog systems, and language in general to share state-of-the-art approaches, best practices, and future directions in multi-modal AI. In addition to invited talks from established researchers, we invite submissions of extended abstracts of at most 2 pages describing work in the relevant areas including: Visual Question Answering, Visual Dialog, (Textual) Question Answering, (Textual) Dialog Systems, Commonsense knowledge, Vision + Language, etc. The submissions are not specific to any challenge track. All accepted abstracts will be presented as posters at the workshop to disseminate ideas. The workshop is on June 19, 2021, at the IEEE Conference on Computer Vision and Pattern Recognition, 2021.
Invited Speakers
Raquel Fernández
University of Amsterdam
Vittorio Ferrari
He He
New York University
Anirudh Koul
Olga Russakovsky
Princeton University
Aida Nematzadeh
DeepMind
Justin Johnson
University of Michigan
Damien Teney
Idiap Research Institute
Mohit Bansal
UNC Chapel Hill
Katerina Fragkiadaki
Carnegie Mellon University
Program
Live
Prerecorded
|
|
 |
Welcome
Aishwarya Agrawal (University of Montreal / Mila / Deepmind) [Video] [Slides] |
|
|
|
Invited Talk
Title: Visual & Conversational Saliency Raquel Fernández (University of Amsterdam) [Video] [Slides] |
|
|
|
Invited Talk
Title: Connecting Vision and Language with Localized Narratives and Open Images Vittorio Ferrari (Google) [Video] [Slides] |
|
|
|
Invited Talk
Title: Towards Overcoming the Language Prior in VQA He He (New York University) [Video] [Slides] |
|
|
|
Invited Talk
Title: How AI Can Empower The Blind Community Anirudh Koul (Pinterest) [Video] [Slides] |
|
|
|
Invited Talk
Title: Models, metrics, tasks and fairness in vision and language Olga Russakovsky (Princeton University) [Video] [Slides] |
|
|
 |
VQA Challenge Talk (Overview, Analysis and Winner Announcement)
Ayush Shrivastava (Georgia Tech) [Video] [Slides] Poster ID: 12 |
|
|












|
VQA Challenge Winner Talk
Team: AliceMind Members: Ming Yan, Haiyang Xu, Chenliang Li , Junfeng Tian, Wei Wang, Bin Bi, Zheng Cao, Ji Zhang, Songfang Huang, Fei Huang, Luo Si Affiliation: Alibaba Group [Video] [Slides] Poster ID: 13 |
|
|
 |
TextVQA Challenge Talk (Overview, Analysis and Winner Announcement)
Yash Kant (Georgia Tech) [Video] [Slides] Poster ID: 14 |
|
|
TextVQA Challenge Winner
Members: Yixuan Qiao, Hao Chen, Jun Wang, Xianbin Ye, Ziliang Li, Peng Gao, Guotong Xie [Paper] Poster ID: 15 |
|
|
|
|
Poster Spotlights
To watch the poster spotlights, visit: https://visualqa.org/posters_2021. |
|
|
 |
TextCaps Challenge Talk (Overview, Analysis and Winner Announcement)
Amanpreet Singh (Facebook AI Research) [Video] [Slides] Poster ID: 16 |
|
|












|
TextCaps Challenge Winner Talk
Members: Zhengyuan Yang, Jianfeng Wang, Xiaowei Hu, Zhe Gan, Lijuan Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Jiebo Luo, Zicheng Liu Affiliations: Microsoft, University of Rochester [Video] [Slides] Poster ID: 17 |
|
|
|
Invited Talk
Title: Towards Better Multimodal Pretraining Aida Nematzadeh (DeepMind) [Video] [Slides] |
|
|
|
Invited Talk
Title: Learning Visual Representations from Language Justin Johnson (University of Michigan) [Video] [Slides] |
|
|
|
Invited Talk
Title: Visual question answering and the limits of statistical learning. Are we building a ladder to the moon? Damien Teney (Idiap Research Institute) [Video] [Slides] |
|
|
|
Invited Talk
Title: Knowledgeable & Spatial-Temporal Vision+Language Mohit Bansal (UNC Chapel Hill) [Video] [Slides] |
|
|
|
Invited Talk
Title: Augment Machine Intelligence with Multimodal Information Katerina Fragkiadaki (Carnegie Mellon University) [Video] [Slides] |
|
|
|
Closing Remarks
Aishwarya Agrawal (University of Montreal / Mila / Deepmind) [Video] [Slides] |
Submission Instructions
We invite submissions of extended abstracts of at most 2 pages (excluding references) describing work in areas such as: Visual Question Answering, Visual Dialog, (Textual) Question Answering, (Textual) Dialog Systems, Commonsense knowledge, Video Question Answering, Video Dialog, Vision + Language, and Vision + Language + Action (Embodied Agents). Accepted submissions will be presented as posters at the workshop. The extended abstract should follow the CVPR formatting guidelines and be emailed as a single PDF to the email id mentioned below.
-
Dual Submissions
We encourage submissions of relevant work that has been previously published, or is to be presented at the main conference. The accepted abstracts will not appear in the official IEEE proceedings.
Where to Submit?
Please send your abstracts to visualqa.workshop@gmail.com
Dates
March 2021
Challenge Announcements
May 21, 2021
Extended
Workshop Paper Submission
mid-May 2021
Challenge Submission Deadlines
May 28, 2021
Notification to Authors
June 19, 2021
Workshop
Organizers
Ayush Shrivastava
Georgia Tech
Yash Kant
Georgia Tech

Sashank Gondala
Georgia Tech

Satwik Kottur
Facebook AI

Dhruv Batra
Georgia Tech / Facebook AI Research

Devi Parikh
Georgia Tech / Facebook AI Research
Aishwarya Agrawal
University of Montreal / Mila / Deepmind
Sponsors
This work is supported by grants awarded to Dhruv Batra and Devi Parikh.
Contact: visualqa.workshop@gmail.com