
|
|
 |
Welcome
Dhruv Batra (Georgia Tech) |
|
|
 |
Transfer of Specialized Knowledge for Vision-Language Tasks
Invited Talk: Svetlana Lazebnik (UIUC) [Slides] |
|
|
 |
Answering Visual Questions with End-to-End Module Networks and Explaining Decisions
Invited Talk: Marcus Rohrbach (Facebook AI Research) [Slides] |
|
|
 |
Why Did You Say That? Explaining and Diversifying Captioning Models
Invited Talk: Kate Saenko (Boston University) [Slides] |
|
|
|
Morning Break |
|
|
 |
Dangers and Opportunities in Research with VQA
Invited Talk: Derek Hoeim (UIUC) [Slides] |
|
|
 |
Overview of EvalAI
Deshraj Yadav (Georgia Tech) [Slides] |
|
|
  |
Overview of dataset, challenge, winner announcements, analysis of results
Yash Goyal (Virginia Tech), Aishwarya Agrawal (Virginia Tech) [Slides] |
|
|






|
Challenge Runner-Up Talk
Zhou Yu, Jun Yu, Chenchao Xiang, Dalu Guo, Jianping Fan and Dacheng Tao [Slides] |
|
|




|
Challenge Runner-Up Talk
YoungChul Sohn, Kibeom Lee, Jong-Ryul Lee and Gyu-tae Park |
|
|







|
Challenge Winner Talk
Damien Teney, Peter Anderson*, David Golub*, Po-Sen Huang, Lei Zhang, Xiaodong He and Anton van den Hengel [Slides] |
|
|
|
Lunch |
|
|
 |
VQA, and why it's asking the wrong question
Invited Talk: Anton Van Den Hengel (University of Adelaide) [Slides] |
|
|
 |
Teaching Machines to Describe Images via Human Feedback
Invited Talk: Sanja Fidler (University of Toronto) |
|
|

|
Poster session and Afternoon break |
|
|
 |
Unifying QA, Dialog, VQA and Visual Dialog
Invited Talk: Jason Weston (Facebook AI Research) [Slides] |
|
|
 |
Visual Dialog
Invited Talk: Abhishek Das (Georgia Tech) [Slides] |
|
|
 |
GuessWhat?! Visual object discovery through multi-modal dialogue
Invited Talk: Hugo Larochelle (Google Brain) [Slides] |
|
|
|
Panel
Future Directions |
|
|
 |
Closing Remarks
Devi Parikh (Georgia Tech) |
VQA Challenge Workshop
Location: Room 301AB, Hawaii Convention Center
at CVPR 2017, July 26, Honolulu, Hawaii, USA
Home Program SubmissionAccepted Abstracts
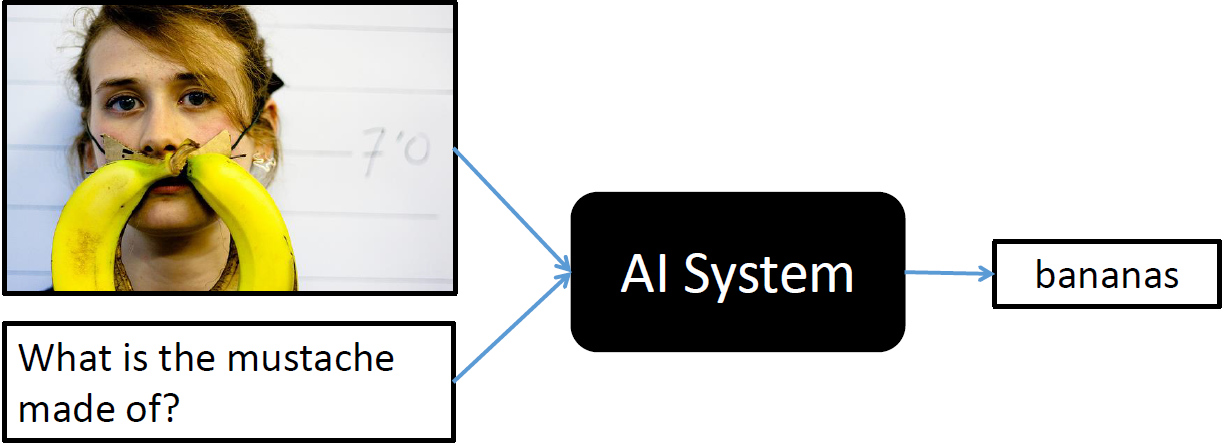
Introduction
The primary purpose of this workshop is to hold the 2nd edition of the Visual Question Answering Challenge on the 2nd edition (v2.0) of the VQA dataset introduced in Goyal et al., CVPR 2017. The 1st edition of the VQA Challenge was organized in CVPR 2016 on the 1st edition (v1.0) of the VQA dataset introduced in Antol et al., ICCV 2015. VQA v2.0 dataset is a more balanced version of VQA v1.0 which significantly reduces the language biases. VQA v2.0 is about twice the size of VQA v1.0.
Our idea in creating this new “balanced” VQA dataset is the following: For every (image, question, answer) triplet (I,Q,A) in the VQA v1.0 dataset, we identify an image I’ that has an answer A’ to Q such that A and A’ are different. Both the old (I,Q,A) and the new (I’,Q,A’) triplets are present in the VQA v2.0 dataset balancing the VQA v1.0 dataset on a per question basis. Since I and I’ are semantically similar, a VQA model will have to understand the subtle differences between I and I’ to provide the right answer to both images. It cannot succeed as easily by making “guesses” based on the language alone.
This workshop will provide an opportunity to benchmark algorithms on VQA v2.0 and to identify state-of-the-art algorithms that need to truly understand the image content in order to perform well on this balanced VQA dataset. A secondary goal of this workshop is to continue to bring together researchers interested in Visual Question Answering to share state-of-the-art approaches, best practices, and future directions in multi-modal AI.
In addition to invited talks from established researchers, we invite submissions of extended abstracts of at most 2 pages describing work in the areas relevant to Visual Question Answering such as: Visual Question Answering, (Textual) Question Answering, Dialog, Commonsense knowledge, Video Question Answering, Image/Video Captioning, Language + Vision. Accepted submissions will be presented as posters at the workshop. The workshop will be held on July 26th, 2017 at the IEEE Conference on Computer Vision and Pattern Recognition, 2017.
Invited Speakers
Abhishek Das
Georgia Tech
Sanja Fidler
University of Toronto
Derek Hoeim
University of Illinois at Urbana-Champaign
Hugo Larochelle
Google Brain
Svetlana Lazebnik
University of Illinois at Urbana-Champaign
Marcus Rohrbach
Facebook AI Research
Kate Saenko
Boston University
Anton Van Den Hengel
University of Adelaide
Jason Weston
Facebook AI Research
Program
Poster Presentation Instructions
1. Poster stands will be 8 feet wide by 4 feet high. Please review the CVPR17 poster template for more details on how to prepare your poster. You do not need to use this template, but please read the instructions carefully and prepare your posters accordingly.
2. Poster presenters are asked to install their posters between 12:15 PM and 1:45 PM. Push pins will be provided for attaching posters to the boards.
Submission Instructions
We invite submissions of extended abstracts of at most 2 pages describing work in areas such as: Visual Question Answering, (Textual) Question Answering, Dialog, Commonsense Knowledge, Video Question Answering, Image/Video Captioning and other problems at the intersection of vision and language. Accepted submissions will be presented as posters at the workshop. The extended abstract should follow the CVPR formatting guidelines and be emailed as a single PDF to the email id mentioned below. Please use the following LaTeX/Word templates.
Dual Submissions
We encourage submissions of relevant work that has been previously published, or is to be presented at the main conference. The accepted abstracts will be posted on the workshop website and will not appear in the official IEEE proceedings.
Dates
May 28, 2017 Extended
Submission Deadline
May 29, 2017
Decision to Authors
Organizers
Aishwarya Agrawal
Virginia Tech
Yash Goyal
Virginia Tech

Tejas Khot
Virginia Tech

Peng Zhang
Virginia Tech

Jiasen Lu
Virginia Tech

Larry Zitnick
Facebook AI Research
Dhruv Batra
Georgia Tech
Devi Parikh
Georgia Tech
Webmaster

Akrit Mohapatra
Virginia Tech
Contact: visualqa@gmail.com